Rails Girls can be a very chaotic experience which throws you in the middle of an overwhelming pile of technology. But if you survived it and are willing to learn the things properly at your own pace, this post outlines some pointers.
It's easy to get started in making websites, but as soon as you enter the territory of programming logic, the learning curve rises sharply. You should be aware of your motives that why you are getting into software development. If you want to do it just because you've heard it pays well, it's probably not enough. Wanting to create a solution to some need that you and others have is more motivating and helps in focusing your efforts. Also it helps if you enjoy problem solving and figuring out how things work, because that's what you'll be doing every day.

Here is a roadmap of things you will need to learn sooner or later. The effort required for learning them is expressed using chili peppers.  can be learned in a few days, requires some weeks of focused learning, and will take many months.
can be learned in a few days, requires some weeks of focused learning, and will take many months.
I want to create a web site or app
You will need to learn HTML, which is the language that every web site and web application is made out of. There is a good overview in MDN's Learning the Web guide.
Though you can learn HTML with all the files on just your own computer, eventually you will need a server for hosting your web site so that also others can see it. You can get started with GitHub Pages.
I want my site to look pretty
You will need to learn CSS, which is the language for describing the fonts, colors and layouts of web sites. You can learn bits of CSS easily as you go, though learning the intricacies of CSS layouts means at least worth of fiddling.
I want my site to do things
You will need to learn programming. The exact choice of language doesn't matter much. The hard part is learning to think like a programmer, but after you can program in one language, you can learn another language in a matter of days or weeks.
In order to change a web page while the user is on it, you will have to use JavaScript. In order to generate different HTML when the user enters or reloads a web page, any general purpose programming language can be used, such as Ruby.
I want my site to remember things
Almost every application uses a database for storing information. You will need to learn the basics of SQL, which is the language for communicating with a relational database (for example PostgreSQL). Another popular kind of database is a document database (for example CouchDB), in which case the query language is usually something other than SQL.
I can't understand the code I wrote last month
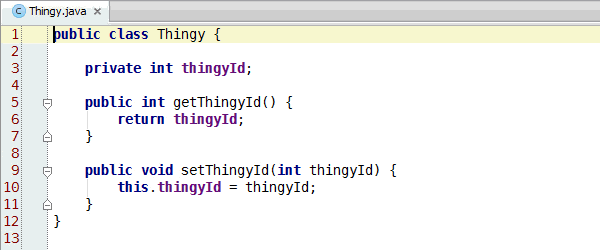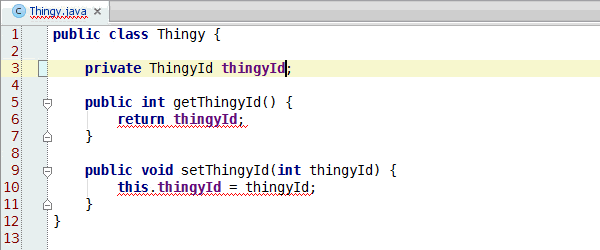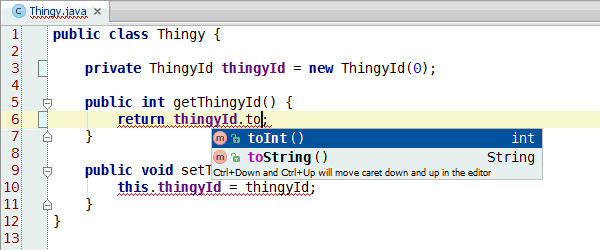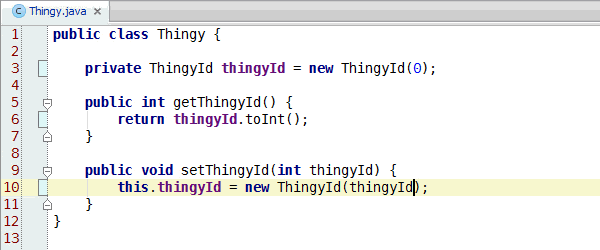
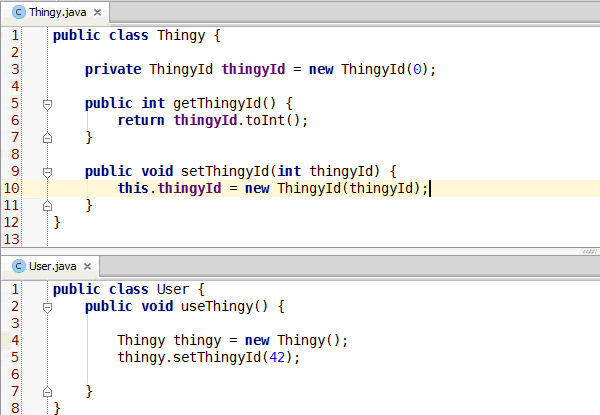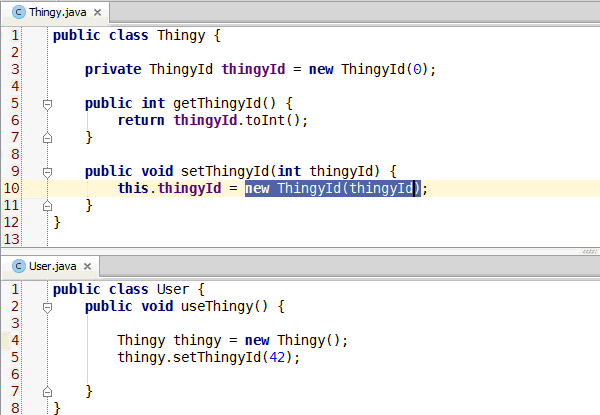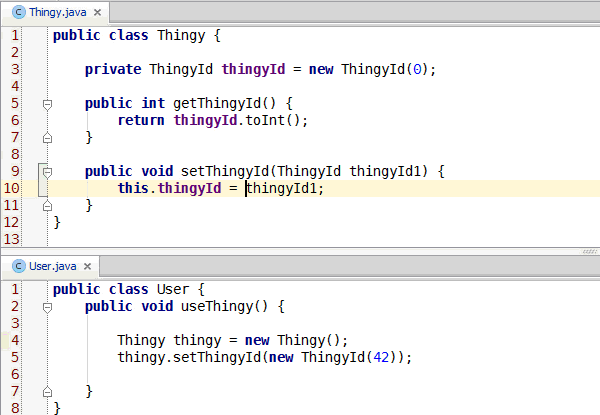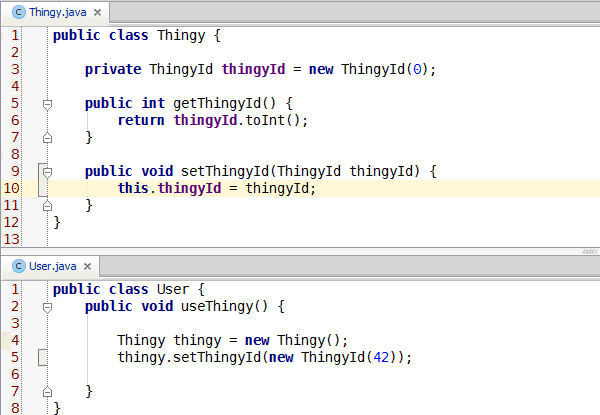
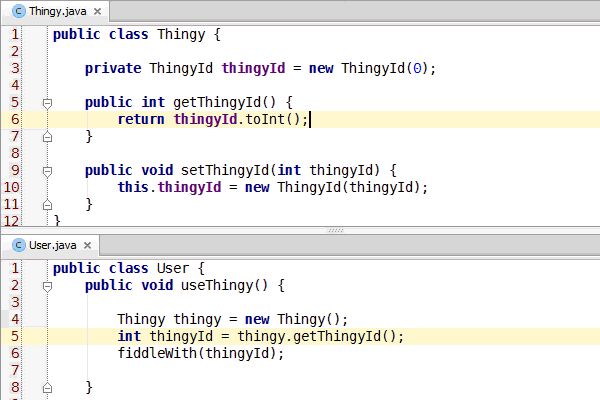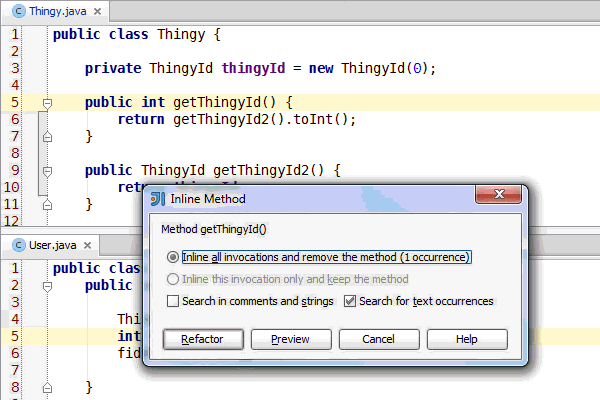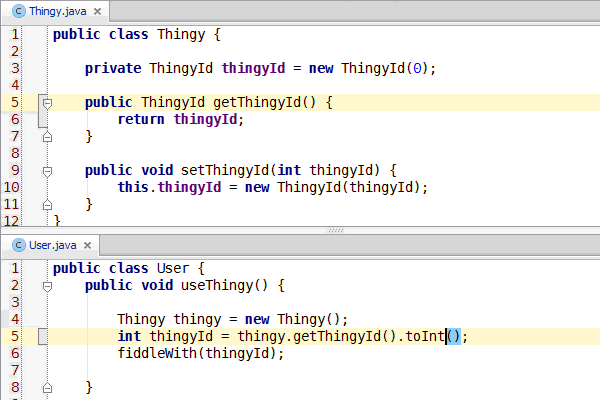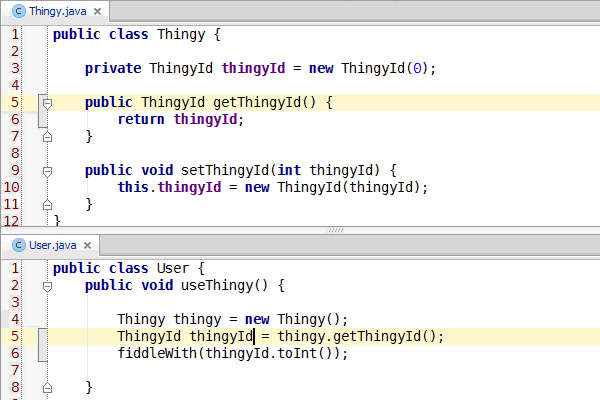
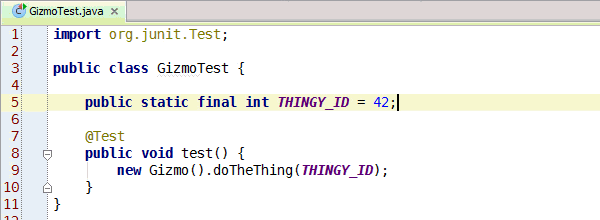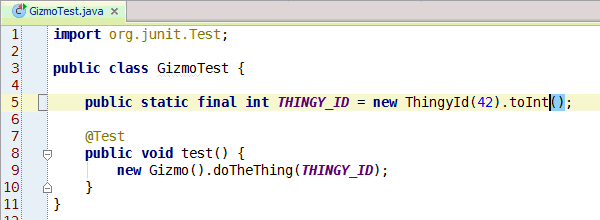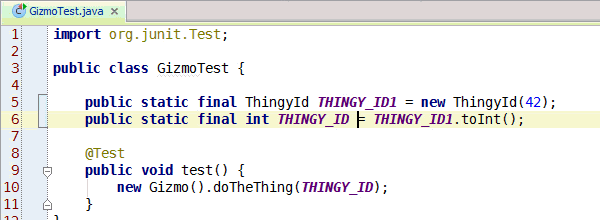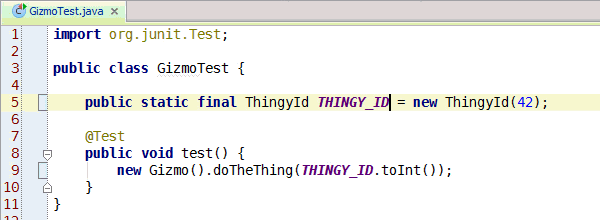
Congratulations, you've learned enough programming to be dangerous. Anybody can write code that the computer understands, but it requires skill to write code that other programmers can understand. You should start learning the principles of writing good code. Clean Code: A Handbook of Agile Software Craftsmanship is a good starting point and my site has additional resources.
My code doesn't always work right
To make sure that the code does what you think it should do, you should write automated tests for it. This can be done by learning Test-Driven Development which will guarantee that all the code you write is tested. TDD Tetris Tutorial is a good starting point.
I want to work on a project together with others
Version control is used for sharing code changes with other developers. It's also useful when working alone, because it lets you reliably return to earlier versions of your code and also works as a backup. The most popular choice is using the Git version control system and the GitHub repository hosting service.
I have a question
The first step in solving a problem is doing a Google search. If you can't find an answer, then for programming related questions you can post your question on Stack Overflow, but first learn how to make an SSCCE to get your code related questions answered. It's also good to visit meetups to get in touch with the local developer community and talk with other developers, especially for questions which have multiple correct answers (e.g. "which tool or language should I use for X").
I want a job
To get a job in technology, more important than your CV or degrees is that you have some projects which you can showcase. Create a complete application, make it available for others to use and put its code up on GitHub. Start a blog and post there regularly things you've learned and what you're thinking about. Attend local meetups regularly and discuss with other developers to get some contacts and to hear about open positions for a junior developer.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}