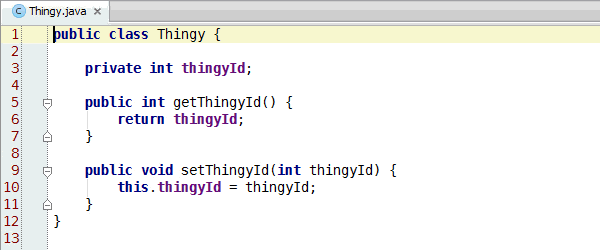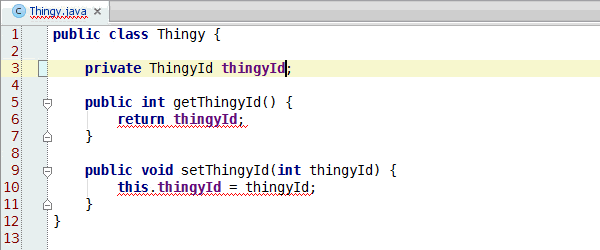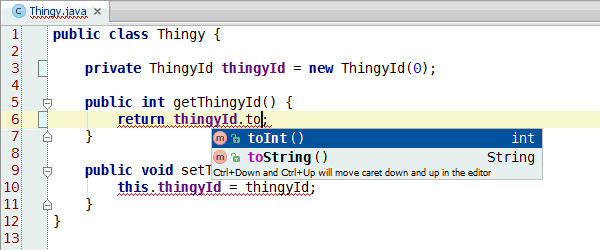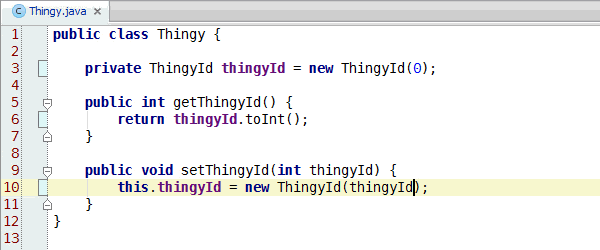
Jumi test runner version 0.4 adds JUnit backward compatibility, so that Jumi can run existing JUnit tests out-of-the-box. All testing frameworks that can be run with JUnit may also be run on Jumi, so there is a low barrier of entry.
One advantage for JUnit users to try out Jumi is faster test execution. In this article I'm showing some benchmark results of the current (non-optimized) Jumi version, and estimates of how much more faster it will at least get once I implement some performance optimizations.
Class Loader Overhead
According to earlier experiences of parallelizing JUnit, "for a fairly optimized unit-test set, expect little or no gain - maybe 15-20%." That's because of the overhead of class loading. With Java 7 the class loaders are at least parallel capable, but I'm still expecting it to affect the test run times considerably.
That's why in this benchmark I'm using a project that has exactly such CPU-bound unit tests. It'll be much more interesting than looking at slow or IO-bound integration tests that scale much more easily to multiple CPU cores. ;)
Benchmark Setup
As a test subject I'm using the unit tests from Dimdwarf's core module (mixed Java and Scala). It has over 800 unit tests, they all are CPU-bound and take just a few of seconds to run. Over half of the tests have been written using JDave, a Java testing framework that runs on JUnit. The rest have been written using Specsy, a testing framework for Java, Scala, Groovy and with little effort any other JVM based language. Specsy 1 ran on JUnit, but Specsy 2 runs on Jumi, which allows test method level parallelism and solves a bunch of issues Specsy had with JUnit's limited execution model. Running JUnit tests on Jumi is limited to test class level parallelism (until JUnit itself implements Jumi support).
All measurements were run on Core 2 Quad Q6600 @ 3.0 GHz, 4 GB RAM, jdk1.7.0_07 64bit, Windows 7. The measurements were repeated 11 times and the median run times are reported. The program versions used were: Jumi 0.4.317, JUnit 4.8.2, IntelliJ IDEA 12.0.3 UE, Maven Surefire Plugin 2.13.
For those measurements which were started from IntelliJ IDEA, the Java compiler and code coverage were disabled to avoid their latency and overhead. The measurement was started when IDEA's Run Tests button was clicked, and stopped when IDEA showed all tests finished. The time was measured at 1/30 second accuracy using a screen recorder (that recorded just a small screen area - barely noticable on CPU usage).
For those measurements which were started from Maven, the time was measured starting from when the text "maven-surefire-plugin:2.13:test" shows up, until the "Results" line shows up. The time was measured using a screen recorder, same as above.
For the synthetic Jumi benchmarks which estimate future optimizations, the time was measured using System.currentTimeMillis() calls inside the Jumi test runner daemon process. Also Jumi was modified to run the test suite inside the same JVM multiple times (because I haven't yet implemented connecting to an existing test runner daemon process). It's safe to assume that the inter-process communication latency is much smaller than 100 ms, so the results should be fairly accurate.
The Results
Click to see them bigger.

Benchmark 1: JUnit, IDEA-JUnit, 1 thread
As a baseline the tests were run with the JUnit test runner from within IDEA. JUnit doesn't support parallel execution, so this test run was single threaded. The result was 5.8 seconds.
Benchmark 2: JUnit, Maven Surefire, 1 thread
As another baseline the Maven Surefire Plugin was used, which gave 5.0 seconds. Surprisingly Maven was much faster than IDEA's JUnit integration. This is probably due to the initialization that IDEA does in the beginning of a test run, presumably to discover the test classes and create a list of the tests to be run, or then related to the real-time test reporting.
Though Surefire supports running tests in parallel, I wasn't able to make it work - it threw a NullPointerException inside the Surefire plugin, probably due to an incompatibility with the Specsy 1 testing framework. Since JUnit was not originally designed to run tests in parallel and JUnit is very relaxed in what kinds of events it accepts from testing frameworks, this kinds of incompatibilities are to be expected.
Benchmark 3: Jumi, IDEA-JUnit, 1 thread
This was run with the Jumi 0.4 test runner, but since it doesn't yet have IDE integration, the test run was bootstrapped from a JUnit test which was started using IDEA. So it has the overhead of one extra JVM startup and IDEA's test initialization.
The result was one second slower than running JUnit tests directly with IDEA. Based on my experiences, a bit over half a second of that is due to the time it takes to start a second JVM process for the Jumi daemon. The rest is probably due to the class loading on the Jumi launcher side - for example at the moment it uses for communication Netty, which is quite a big library (about 0.5 MB of class files), so loading its classes takes hundreds of milliseconds.
Benchmark 4: Jumi, IDEA-JUnit, 4 threads
As expected, running on multiple threads does not make unit tests much faster. Adding threads takes Jumi from 6.8 seconds to 5.1 seconds, only 25% less time, barely cancelling out the overhead of the extra JVM creation.
As we'll see, the majority of the time is spent in class loading. Also this Jumi version has not yet been optimized at all, so the class loading overhead is probably even more severe than it needs to be (one idea I have is to run in parallel threads tests that use a different subset of classes - that way they shouldn't be blocked on loading the same classes that much).
Benchmark 5: Jumi, IDE integration (estimated), 1 thread
This benchmark measures how fast Jumi would be with IDE integration. This was measured around the code that launches Jumi and shows the test results, as it would be done by an IDE. Since this code would run in the same process as the Java IDE, the measurement was done in a loop inside one JVM instance, to eliminate the overhead of class loading on the Jumi launcher side and to let the JIT compiler warm up.
This gives about the same results as running JUnit tests directly in IDEA. Though it's not as fast as Surefire, maybe because Surefire's test reporting is more minimal, or because Jumi's daemon side has more class loading overhead for its own internal classes (as mentioned abobe when discussing benchmark 3).
Benchmark 6: Jumi, IDE integration (estimated), 4 threads
The absolute speedup over 1 thread is about the same as before (under 2 seconds), but with the JVM startup overhead away we are now on the winning side.
Benchmark 7: Jumi, persistent daemon process (estimated), 1 thread
Jumi's daemon process, which runs the tests, will eventually be reused for multiple test suite runs. The benefits of that feature were estimated by modifying Jumi to run the same tests multiple times in the same JVM.
This avoids the JVM startup overhead completely on subsequent test suite runs, and the JIT compiler starts kicking in for Jumi's internal classes (the first suite run is about 1 second slower). At 4.5 seconds we are now better than JUnit also in single-threaded performance.
Benchmark 8: Jumi, persistent daemon process (estimated), 4 threads
With 4 threads we see the same about 2 second speedup over a single thread as before. The tests are still dominated by the same amount of class loader overhead as before, but now we are anyways down by 50%, or 2× faster than JUnit.
Benchmark 9: Jumi, class loader caching of dependencies (estimated), 1 thread
For this benchmark Jumi was modified further to reuse the class loader that loads all libraries used by the system under test. In this particular project this includes big libraries such as the Scala standard library, Google Guice, Apache MINA and CGLIB. The project's own production and test classes, as well as some testing libraries (that didn't work well with multiple class loaders), were not cached, but their class loader was re-created for each test suite run.
We see a 40% improvement over just the persistent daemon process, the same speedup as if we had used multiple threads. The JIT compiler starts now kicking in, so that the full speed is reached only on the third or fourth test suite run (1st run 5.2s, 2nd run 3.1s, 3rd run 3.0s, 4th run 2.7s) after it has had some time to optimize the library dependencies' code.
Benchmark 10: Jumi, class loader caching of dependencies (estimated), 4 threads
With 4 threads we are down to 1.4 seconds, an improvement of 75%, already 4× faster than JUnit!
Benchmark 11: Jumi, class loader caching of all classes (estimated), 1 thread
This is an estimate of the ideal situation of having no class loader overhead. In this benchmark Jumi was modified to create just a single class loader for both the dependencies and application classes, and then reuse that for all test suite runs. After the first run there is no more class loading to be done, and on the third or fourth run the JIT compiler has optimized it.
We see that under ideal circumstances, it takes only 1.6 seconds to run all the tests single-threadedly. It's arguable whether the class loading overhead can be eliminated this much with techniques such as reloading classes without hurting reliability.
Benchmark 12: Jumi, class loader caching of all classes (estimated), 4 threads
With 4 threads we get down to 0.9 seconds, which is about 50% less time than the single-threaded benchmark. The ideal speedup on 4 cores would have been 75%, down to 0.4 seconds. This shows us that there is some contention that needs to be optimized inside Jumi. One possible area of improvement is the message queues - now all test threads write to the same queue, which violates the single writer principle, and also it doesn't take advantage of batching.
Conclusions
In this benchmark we only looked at speeding up a fast unit test suite, which are notoriously hard to speed up on the JVM. Slow integration tests should get much better speed improvements when run on multiple CPU cores. In the Jumi wiki there are some tips on how to make integrations tests isolated, so that they can be run in parallel.
Jumi's JUnit compatibility gives the ability to run JUnit tests in parallel at the test class level. For test method level parallelism the testing frameworks must implement the Jumi Driver API. Right now you can get that full parallelism with Specsy for all JVM based languages (at the moment Scala/Groovy/Java, but creating a wrapper for a new languages is simple) and hopefully other testing frameworks will follow suit.
Once somebody* implements IDE integration for Jumi, its single-threaded speed will be on par with older test runners, and its native parallel test execution will push it ahead. In near future, when Jumi implements the persistent daemon process, class loader caching, test order priorization (run the most-likely-to-fail tests first, similar to JUnit Max) and other optimizations, it will be the fastest test runner ever. :)
* I'll need to rely on the expertise of others who have IDE plugin development experience. Three big IDEs is too much for one small developer... :(
You can get started on using Jumi through Jumi's documentation. You're welcome to ask questions on the Jumi mailing list. Please come there to tell us that which features you would like to see implemented first. Testing framework, IDE and build tool developers are especially encouraged to get in touch, to tell about their needs and to develop tool integration.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}