I've been spending this evening converting the repositories of my old projects from SVN to Git. I used to have the repositories hosted on my home server, but now I've moved them to GitHub (see my GitHub profile). Here I have outlined the procedures that I used to convert my source code repositories.
Preparations
First I installed svn2git, because it handles tags and branches much better than the basic git svn clone command. I run Git under Cygwin, so first I had to install the ruby package using Cygwin Setup. And since Cygwin's Ruby does not come with RubyGems, I downloaded and installed it manually using these instructions.
When RubyGems was installed, I was able to type the following commands to finally install svn2git from GitHub:
gem sources -a http://gems.github.com
gem install nirvdrum-svn2git
Most of my SVN repositories were already running on my server, so accessing them was easy. But for some projects I had just a tarballed version of the repository. For those it was best to run svnserve locally, because git-svn is was not able to connect to a SVN repository through the file system. So I unpacked the repository tarballs into a directory X (so that the individual repositories are subdirectories of X), after which I started svnserve with the command "svnserve --daemon --foreground --root X". Then I could access the repositories through "svn://localhost/name-of-repo" URLs.
You will also need to write an authors file which lists all usernames in the SVN repositories and what their corresponding Git author names should be. The format is as follows, one user per line:
loginname = Joe User <user@example.com>
I placed the authors.txt file into my working directory, where I could easily point to it when doing the conversions.
Simple conversions
When the SVN repository uses the standard layout and its version history does not have anything weird happening, then the following commands could be used to convert the repository.
First make an empty directory and use svn2git to clone the SVN repository:
mkdir name-of-repo
cd name-of-repo
svn2git svn://localhost/name-of-repo --authors ../authors.txt --verbose
When that is finished, check that all branches, tags and version history were imported correctly:
git branch
git tag
gitk --all
You will probably want to publish the repository, so create a new repository (in this example I use GitHub) and push your repository there. Remember to include all branches and tags:
git remote add origin git@github.com:username/git-repo-name.git
git push --all
git push --tags
After that you better clone the published repository from the central server, the way you normally do (cd /my/projects ; git clone git@github.com:username/git-repo-name.git), and delete the original repository which was used when importing from SVN, to get rid of all the SVN related files in the .git directory.
You might also want to add .gitignore file into your project. For my projects I use the following to keep Maven's build artifacts and IntelliJ IDEA's workspace file out of version control:
/*.iws
/target/
/*/target/
Complex conversions
I had one SVN repository where the repository layout had been changed in the middle of the project. At first all project files had been in the root of the repository ("/"), after which they had been moved into /trunk. This caused that when I imported the SVN repository using the standard layout options, the history stopped where that move was made, because before that point in history there was no /trunk. I wanted to import a clean history, so that this mess would not be reflected in the resulting Git repository's history.
What I did, was that first I imported the latter part of the history which used the standard layout:
mkdir messy-repo.2
cd messy-repo.2
svn2git svn://localhost/messy-repo/trunk --rootistrunk --authors ../authors.txt --verbose
Then I imported the first part of the history which used the trunkless layout. This also includes the latter part of the history, but with all files moved under a /trunk directory:
mkdir messy-repo.1
cd messy-repo.1
svn2git svn://localhost/messy-repo --rootistrunk --authors ../authors.txt --verbose
Then I created a new repository where I would be combining the history from those two repositories. I cloned it from the repository with the first part of the clean history.
git clone file:///tmp/svn2git/messy-repo.1/.git messy-repo.combined
cd messy-repo.combined
Then I would start a branch "old_master" from the current master, just to be sure not to lose it. I would also make a tag "after_mess" for the commit that changed the SVN repository layout, and a tag "before_mess" for the commit just before that, where all project files were still cleanly in the repository root.
Did I mention, that the layout changing commit did also add one file, in addition to just changing the repository layout? So I had to recover that change from the otherwise pointless commit. First I had do get a patch with the desirable changes. So I hand-copied from SVN the desired file, checked out the version in Git just before the mess, made the desired change to the working copy, committed it and tagged it so that it would not be lost.
cd messy-repo.combined
git checkout before_mess
git add path/to/the/DesiredFile.java
git commit -m "Recovered the desired file from the mess"
git tag desired_changes
Then I would make a patch with just that once change:
git format-patch -M -C -k -1 desired_changes
Which then created the file 0001-desired-changes.patch.
I needed also clean patches for the latter part of the version history. So I created patches for all changes in the messy-repo.2 repository.
cd messy-repo.2
git format-patch -M -C -k --root master
Then I would hand-edit the 0001-desired-changes.patch file to contain the same date and time as the original commit that messed up the repo. I would also remove the patch for that commit from the patches produced by messy-repo.2.
Then it was time to merge the patches into the first part of the history:
cd messy-repo.combined
git checkout before_mess
git am -k 0001-desired-changes.patch
git am -k patches-from-repo-2/00*
git branch fixed_master
git checkout fixed_master
That way all the history was saved, even the author dates were unchanged (commit dates did however change to current time when using patches - it's possible to rewrite the commit dates using git filter-branch). After that I could just clean up the branches and push it to the central repository as normally.
2009-05-08
Version number management for multi-module Maven projects
I've been thinking about how to best organize the Maven modules in Dimdwarf. My requirements are that (1) the version number of the public API module must stay the same, unless there are changes to the public API, (2) opening and developing the project should be easy, so that I can open the whole project with all its modules by opening the one POM in IntelliJ IDEA, and (3) all code for the project should be stored in one Git repository, so that the version history for all modules is combined and checking out the whole project can be done with one command.
The project structure is currently as follows (these nice graphs were produced with yEd).
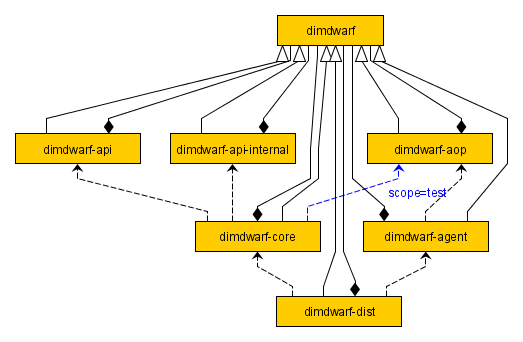
I have one POM module, "dimdwarf", at the root of the project directory. It is the parent of all other modules (that's where dependencyManagement and the common plugins are configured) and it also has as submodules all other modules. The "dimdwarf-api" module is what all users of my framework will depend on, so I want its version numbers to change very rarely - only when the API is changed, not every time that I release just a new version of the server implementation. The "dimdwarf-aop" and "dimdwarf-agent" modules handle the bytecode manipulation and they are needed as part of the bootstrap process. "dimdwarf-core" does not use the AOP classes directly, but it has a dependency to "dimdwarf-aop" for testing purposes. The module "dimdwarf-dist" assembles all other modules together and builds a redistributable ZIP file.
Yesterday I was looking for a solution for reaching my requirements. StackOverflow did not have any existing questions which would have touched exactly this problem, but in one of the answers there was a link to Oliver's blog post which matched my situation perfectly (also read the follow-up). He proposed a solution that checks for consistency in the project structure and fails the build if the modules have dependencies with a wrong version.
After thinking about that some, I came up with a possibly better way to manage the version numbers. It would be a tool (possibly implemented as a Maven plugin) that helps in updating the module version numbers. The tool would be called "module version bumper" or similar. Its commands should be run the directory that contains the project's "workspace POM" (one that has as submodules all modules of the project, but none of the modules depend on it), so that the tool can find all modules that are part of the project.
For the version bumper to work with Dimdwarf, the project structure needs to be refactored:
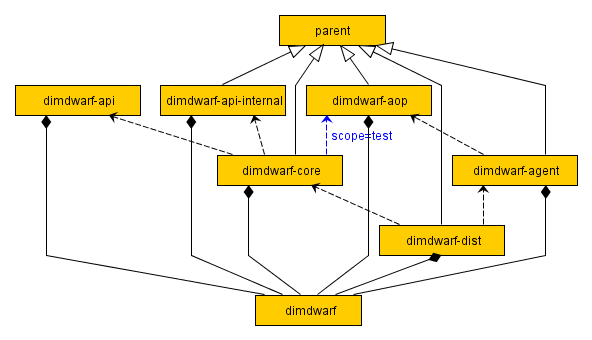
All the common settings (dependencyManagement, plugins etc.) are in the "parent" POM file, which the other modules then extend. I decided to make "dimdwarf-api" independent from it, because I don't want library version upgrades to be reflected in the API's version number. (I could also have created "parent-common" and "parent-deps" which extends "parent-common", but let's keep it simple for now and tolerate some duplication in the API's POM.) The workspace POM, "dimdwarf", does not anymore have the added responsibility of being also the parent POM, which helps the project get rid of cyclic dependencies between the POMs.
To explain how the version bumper would work, let's start with an example of the workflow of making changes to the project. In the beginning, version 1.0.0 of Dimdwarf has recently been released and all modules have "1.0.0" as their version number.
parent 1.0.0
dimdwarf-api 1.0.0
dimdwarf-api-internal 1.0.0
dimdwarf-core 1.0.0
dimdwarf-aop 1.0.0
dimdwarf-agent 1.0.0
dimdwarf-dist 1.0.0
dimdwarf 1.0.0
I notice a bug in the "dimdwarf-aop" module, so I need to make changes to it. Since "dimdwarf-aop" now has a release version (i.e. one that does not end with "-SNAPSHOT"), I need to bump its version to be the next development version (i.e. a "-SNAPSHOT" version higher than the previous release version).
In the project's root directory, I run the version bumper tool's command: "mvn version-bump dimdwarf-aop". This command reads the version number of all modules in the project and determines that "1.0.0" is the highest version number in use. Since it is a release version number, the tool prompts me for the next development version, offering "1.0.1-SNAPSHOT" as the default. I accept the default. Then the tool changes that to be the version number of "dimdwarf-aop" and of all modules that depend on "dimdwarf-aop" at runtime ("dimdwarf-core" has only a test-time dependency, so it is not changed). So now the version numbers are as follows, with changes highlighted in blue:
parent 1.0.0
dimdwarf-api 1.0.0
dimdwarf-api-internal 1.0.0
dimdwarf-core 1.0.0
dimdwarf-aop 1.0.1-SNAPSHOT
dimdwarf-agent 1.0.1-SNAPSHOT
dimdwarf-dist 1.0.1-SNAPSHOT
dimdwarf 1.0.1-SNAPSHOT
Then I make some changes in "dimdwarf-aop" to fix the bug and commit it to version control.
Some days after that, I begin making some bug fixes to the "dimdwarf-core" module. I change the code, but forget that I have not bumped that module's version to be next development version. I commit the changes to version control (I use Git), but thankfully I have a pre-commit hook that verifies that all modules with changes use a development version (or a release version that is strictly higher than the version in the previous commit - otherwise you couldn't commit a new release). The commit fails with a message:
The following files were changed in module "dimdwarf-core" which has the release version "1.0.0". Update the module to use a development version with the command "mvn version-bump dimdwarf-core" or recommit with the --no-verify option to bypass this version check.
dimdwarf-core/src/main/java/x/y/z/SomeFile.java
dimdwarf-core/src/main/java/x/y/z/AnotherFile.java
I realize my mistake, so I run the command "mvn version-bump dimdwarf-core". This command reads the version number of all modules in the project and determines that "1.0.1-SNAPSHOT" is the highest version number in use. Since it is a development version number, the tool prompts me for the development version for "dimdwarf-core" module, offering "1.0.1-SNAPSHOT" as the default. I accept the default. Then the tool changes that to be the version number of "dimdwarf-core" and of all modules that depend on "dimdwarf-core" at runtime (only "dimdwarf-dist" and "dimdwarf" depend on it, but since they already have version "1.0.1-SNAPSHOT", they don't need to be updated). So now the version numbers are as follows:
parent 1.0.0
dimdwarf-api 1.0.0
dimdwarf-api-internal 1.0.0
dimdwarf-core 1.0.1-SNAPSHOT
dimdwarf-aop 1.0.1-SNAPSHOT
dimdwarf-agent 1.0.1-SNAPSHOT
dimdwarf-dist 1.0.1-SNAPSHOT
dimdwarf 1.0.1-SNAPSHOT
Now I want to publish the new release, so I run a tool that changes all the development versions to release versions (is there already a Maven plugin that does it?). After that the versions numbers are:
parent 1.0.0
dimdwarf-api 1.0.0
dimdwarf-api-internal 1.0.0
dimdwarf-core 1.0.1
dimdwarf-aop 1.0.1
dimdwarf-agent 1.0.1
dimdwarf-dist 1.0.1
dimdwarf 1.0.1
I commit the changes to version control and tag it as "dimdwarf-1.0.1". I checkout the tag to a clean directory, build it and deploy all the 1.0.1 artifacts to the central Maven repository (the already deployed 1.0.0 version may not be redeployed). I also collect the newly built redistributable ZIP file from the /dimdwarf-dist/target directory and upload it to the web site for download.
So that is my idea for managing version numbers in multi-module Maven projects. What do you think, would a workflow such as this work in practice? Do you think that there will be problems with this version numbering scheme (mixed development and release versions) when using continuous integration or when deploying to a Maven repository (where overwriting previously deployed versions is not allowed)? Would somebody with experience in Maven plugin development be willing to help in implementing this?
2009-05-07
Introduction to Dimdwarf
My current hobby project, Dimdwarf Application Server, will be a scalable high-availability application server and a distributed object database. It lets the application programmer to write single-threaded event-driven code, which the application server will then execute multi-threadedly. The concurrency issues are hidden from the application programmer using STM and DSM. The programming model is the same as what Project Darkstar has (being involved with Darkstar is where I got the idea), but the architecture of the implementation has some differences. As for other similar application servers, there is for example Terracotta, but other than that I don't know similar systems - mostly just distributed caches and databases. My primary motivation for creating Dimdwarf is intellectual challenge, as it will be the most complicated application I have written this far.
Background
In January 2008 I got involved in Project Darkstar, which is an open source application server designed for the needs of MMO games and is developed by Sun Microsystems. I liked its simple programming model, how the objects are automatically persisted and executed transactionally, so that the programmer can concentrate more on the application logic than the concurrency issues. There were some things that I felt could be improved about Darkstar, so I invented transparent references and implemented them in Darkstar (they should be included in the main codebase in near future). There were also some other utilities that I wrote.
Then in June 2008 I got the idea for Dimdwarf and send a mail about it to a couple of other Project Darkstar community members, Emanuel Greisen and Martin Eisengardt, with whom I had been discussing about making development on Darkstar easier. My initial goal was to solve the GPL license and testability issues that Darkstar has: Since Darkstar Server is GPL'd, you can not embed it in a commercial game, for example to make a single-player mode for a multiplayer game, or to distribute the server side of your application without publishing it under GPL. Testing Darkstar applications was hard and you had to use use MockSGS for running unit tests, because Darkstar could not be easily decoupled from the code that uses it. Also debugging Darkstar applications was hard, because you would have to deal with transaction timeouts and multiple threads.
My idea with Dimdwarf was to create a light version of Darkstar Server, one that uses an in-memory database, is single-threaded (at least initially), doesn't use timeouts and has no clustering support (thus making it simple), but you could anyways use a Dimdwarf-to-Darkstar adapter library to run Dimdwarf applications on Darkstar (thus getting the scalability benefits without being infected by GPL, as Dimdwarf uses the BSD license). Even Dimdwarf's name reflects this goal: dim = not smart / synonym for dark, dwarf = small / one kind of a star. Dimdwarf would be light, unintrusive and testing friendly, so that Dimdwarf applications are decoupled from Dimdwarf and you won't need an extensive testing environment and mocking framework to test the applications.
In August 2008 I opened a project page for Dimdwarf at SourceForge and begun writing some code. I was able to reuse the code that I wrote for transparent references, but otherwise I started it from scratch.
Extended Project Goals
Originally I was aiming to keep Dimdwarf as simple as possible and to not make it a scalable high-availability application server. But in January 2009 I read a paper called The End of an Architectural Era and it gave me some ideas about the distributed database design for Darkstar, so I started a thread about it on Darkstar forums. After thinking about it for a couple of days, making a scalable high-availability database did not anymore seem too hard. Extending Dimdwarf to be a high-availability solution started to feel like being within my reach, so I added it to Darkstar's long-term goals.
The high-availability version of Dimdwarf will go under the name Dimdwarf-HA and I've thinking about it passively now for a couple of months. I will first finish the single-node version of Dimdwarf, after which I'll expand it to a clustered multi-node version. The same architecture can be used for both the embedded stand-alone version of Dimdwarf and the clustered Dimdwarf-HA - in fact the new architecture will be much simpler and testable than Dimdwarf's current development version, because it will have less concurrency-aware code.
A following article will discuss Dimdwarf-HA's architecture in more detail.
2009-05-04
Random thoughts on "Random Thoughts"
Previously I've been writing down my thoughts and plans on plain text files, notebooks and paper sheets, but I suppose that it would be good to post some of them also online. It would make referring to them much easier. Maybe someone might even mistake to read them.
First I will probably be writing about my current hobby project, Dimdwarf Application Server, which will be a scalable high-availability application server and a distributed object database, optimized for low latency (for example MMO games). Then I might write things about user interface design. I design UIs using the GUIDe+GDD method and right now I'm writing my masters thesis about the same topic. I may also write things about TDD (next autumn I'll be lecturing a course about TDD in the University of Helsinki) as well as my thoughts on what Software Craftsmanship is about (on SC's mailing list there has not yet been a clear consensus on what makes craftsmen different from other developers).
When thinking about what to call this blog, I remembered a quote from an old AMV, Boogiepop Phantom - Butterfly by MindWarp. I was going to write here whatever random thoughts I happen to have, so I though "Random Thoughts" to be a good name for a blog about random thoughts. It would be nice for them to be as psychedelic as that AMV, but I'm afraid it won't happen. ;)
Butterflies are random thoughts people have
They live, They die, They are pointless.
- Jonathan Watson
First I will probably be writing about my current hobby project, Dimdwarf Application Server, which will be a scalable high-availability application server and a distributed object database, optimized for low latency (for example MMO games). Then I might write things about user interface design. I design UIs using the GUIDe+GDD method and right now I'm writing my masters thesis about the same topic. I may also write things about TDD (next autumn I'll be lecturing a course about TDD in the University of Helsinki) as well as my thoughts on what Software Craftsmanship is about (on SC's mailing list there has not yet been a clear consensus on what makes craftsmen different from other developers).
Subscribe to:
Posts (Atom)