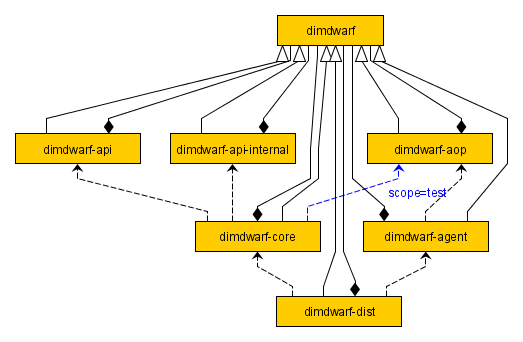
In a previous post I gave an introduction to Dimdwarf - how the project got started and what are its goals. In this post I will explain the planned architecture for Dimdwarf, which should be scalable enough to evolve the system into a distributed application server.
Background
In January 2009 I got tipped by dtrott at GitHub about a white paper called The End of an Architectural Era. It discusses how traditional RDBMS are outdated and that it's time to create database systems which are designed for current needs and hardware. In the paper they describe how they built a distributed high-availability in-memory DBMS which beats a commercial RDBMS in the TPC-C benchmark by almost two orders of magnitude. It keeps all the data in main memory (today's servers have lots of it), thus avoiding the greatest bottleneck in RDBMSs - writing transaction logs on hard disk (today's HDDs are not significantly faster than in the past). It uses a single-threaded execution model, which makes the implementation simpler and avoids the need for locking, yielding a more reliable system with better performance. Failover is achieved by replicating the data on multiple servers. Scalability is achieved by partitioning the data on multiple servers.
I thought that some of these ideas could be used in Darkstar, so I posted a thread about it on Darkstar forums. After thinking about it for a day, I came up with a proposal for how to apply the ideas to Darkstar's multi-node database. And after still a couple more days, the architecture appeared to be so simple that I added the making of a multi-node version to Dimdwarf's roadmap. Using ideas from that paper, it should be relatively simple to implement a distributed application server.
Issues with the current Dimdwarf architecture
Currently Dimdwarf uses locking-based concurrency in its implementation. For example its database and task scheduler contain shared mutable data and use locking for synchronization. As a result, their code is at times quite complex, especially in the database which needs to keep track of consistent views to the data for all active transactions. Also committing the transactions (two-phase commit protocol is used) requires some careful coordination and locking.
There have been some concurrency bugs in the system (one way to find them is to start 20-50 test runs in parallel to force more thread context switches), both in the database [1][2] and the task scheduler [3]. While all found concurrency bugs have been fixed, their existence in the first place is a code smell that the system is too complex and needs to be simplified. As it is said in The Art of Agile Development, in the No Bugs chapter, one must "eliminate bug breeding grounds" and solve the underlying cause:
Don't congratulate yourself yet—you've fixed the problem, but you haven't solved the underlying cause. Why did that bug occur? Discuss the code with your pairing partner. Is there a design flaw that made this bug possible? Can you change an API to make such bugs more obvious? Is there some way to refactor the code that would make this kind of bug less likely? Improve your design.
Some of the tests for the concurrent code are long and complex, which in turn is a test smell that the system is too complex. Lots of effort had to be put into making the tests repeatable [4][5][6][7][8][9][10], for example using CountDownLatch instances to force concurrent threads to proceed in a predictable order. Some of the tests even need comments, because the test code is so complex and inobvious.
All of this indicates that something is wrong with the current architecture. Even though Dimdwarf applications have a simple single-threaded programming model, the Dimdwarf server itself is far from being simple. Of course, the problem being solved by Dimdwarf is complex, but that does not mean that the solution also needs to be complex. It's just a matter of skill to create a simple solution to a complex problem.
Ideas for the new architecture
The paper The End of an Architectural Era gave me lots of ideas on how to simplify Dimdwarf's implementation. The database that was described in the paper, H-Store, is in many ways similar to Dimdwarf and Darkstar. For example all its transactions are local, so as to avoid expensive two-phase commits over the network, and it executes the application logic inside the database itself. But H-Store has also some new ideas that could be applied to Dimdwarf, the main points being:
- The system is single-threaded, which makes its implementation simpler and avoids the need for locking.
- All data is stored in memory, which avoids slow disk I/O. High-availability is achieved through replication on multiple servers.
Single-threadedness
Each H-Store server node is single-threaded, and to take advantage of multiple CPU cores, many server nodes need to be run on the same hardware. This results in simple data structures and good performance, because it will be possible to use simple non-thread-safe data structures and no locking. I liked the idea and thought about how to apply it to Dimdwarf.
I considered having only one thread per Dimdwarf server node, but it would not work because of one major difference between Dimdwarf and H-Store: data partitioning. In H-Store the data is partitioned over server nodes so that each transaction has all the data that it needs on one server node. Dimdwarf has also data partitioning and strives to make the data locally available, but in Dimdwarf the data will move around the cluster as the players of a MMO game move in the game, so the data partitioning needs to be changed all the time. In H-Store the data access patterns are stable, but in Dimdwarf they are fluctuating.
What does data partitioning have to do with the server being single-threaded? When a transaction tries to read data that is not available locally, it will need to request the data from another server node. While waiting for the data, that server node will be blocked and unable to proceed. Also the other server node, that has the data, is already executing some transaction, so it will not be able to reply with the requested data until the current transaction has ended. If Dimdwarf would be completely single-threaded, the latencies would be too high (and low latency is one of the primary goals). Because Dimdwarf can not guarantee full data locality, it needs to do have some internal concurrency to be able to respond quickly to requests from other servers.
But there is one way to make Dimdwarf's internals mostly single-threaded: one main thread and multiple worker threads. The main thread will do all database access, communicating with other server nodes, committing transactions and other core services. All actions in the main thread must execute quickly, in the order of thousands per second. The worker threads will execute the application logic. The application logic is divided into tasks, each task running in its own transaction. It is recommendable for the tasks to be short, in the order of ten milliseconds or less, but also much longer tasks will be allowed (if they do not write data that is modified concurrently by other tasks).
The communication between the main thread and worker threads, and also the communication between server nodes, will happen through message passing (like in Erlang). This will allow each component to be single-threaded, which will simplify the implementation and testing. It will also make low server-to-server response times possible, because each server node's main thread will execute only very short actions, so it will be able to respond quickly to incoming messages. It will also make it easier to take advantage of multiple cores by increasing the number of worker threads. Also no data copying needs to be done when a worker thread requests data from the main thread, because inside the same JVM it's possible to pass just a reference to some immutable data structure instead of copying the whole data structure over a socket.
In-memory database
The second main idea, keeping all data in memory, requires the data to be replicated over multiple server nodes. H-Store implements its replication by relying on deterministic database queries. H-Store executes the same queries (actually "transaction classes" containing SQL statements and program logic) on multiple server nodes in the same order. It does not replicate the actual modified data over the network, but replicates the tasks that do the modifications, and trusts that the tasks execute deterministically, which will result in the same data modifications to be made on the master and backup server nodes.
The determinism of tasks is a too high requirement to Dimdwarf, as it can not trust that the application programmers are careful enough to write deterministic Java code. Determinism is much easier to reach with SQL queries and very little program logic, than with untrusted imperative program code. So Dimdwarf will need to execute the task on one server node and replicate the modified data to a backup server node. Fortunately Dimdwarf's goals (an application server optimized for low latency, for the needs of online games) allow the relaxing on transaction durability, so we can do the replication asynchronously. This helps to minimize the latency from the user's point of view, but permits the loss of recent changes (within the last second) in case of a server failure.
Other ideas
The paper has also other good ideas, for example that the database should be "self-everything" - self-healing, self-maintaining, self-tuning etc. Computers are cheaper than people, so computers should do most of the work without need for human intervention. The database should be able to optimize its performance automatically, without the need for a DBA manually tuning the server parameters. The database should monitor its own state and heal itself automatically, without the need for a server administrator to keep an eye on the system constantly.
I also read the paper Time, Clocks, and the Ordering of Events in a Distributed System, about which I heard from waldo at the Darkstar forums. That paper taught me how to maintain a global ordering of events in a distributed system using Lamport timestamps. Dimdwarf will apply it so that together with each server-to-server message there is a timestamp of when the message was sent, and the receiving server node will update his clock's timestamp to be equal or greater than the message's send timestamp. The timestamp contains a sequentially increasing integer and a server node ID. This scheme may also be used to generate cluster-wide unique ID numbers for database entries.
Overview of Dimdwarf-HA
Dimdwarf will come in two editions - a single-node Dimdwarf and a multi-node Dimdwarf-HA. Here I will give an overview of the architecture for Dimdwarf-HA, but the same architecture will work for both editions. In the single-node version all components just run on the same server node and possibly some of the components may be disabled or changed.
An application will run on one server cluster. The server cluster will contain multiple server nodes (the expected cluster size is up to some tens of server nodes per application). There are a couple of different types of server nodes: gateway nodes, backend nodes, directory nodes and one coordinator node. A client will connect to a gateway node, and the gateway will forward messages from the client to a backend node for processing (and send the replies back to the client). The backend nodes contain the database and they execute all application logic. The directory nodes contain information that in which backend nodes each database entry is, and they may also contain information needed by the system's database garbage collector. The coordinator node does things that are best done by a single authoritative entity, for example signaling all nodes when the garbage collection algorithm's stage changes.
The system will automatically decide that which services will run on which server nodes. Automatic load balancing will try to share the load evenly over all server nodes in the cluster. When some server nodes fail, the other server nodes will do automatic failover and recover the data from backup copies.
A backend node contains one main thread and multiple worker threads. The threads and server nodes communicate through message passing. The main thread takes messages from an event queue one at a time, processes them, and sends messages to its worker threads and to other server nodes. The worker threads, which execute the application logic, communicate with messages only with their main thread. The same is true for all plugins and other components that run inside a server node - the main thread is the only one that can send messages to other server nodes, and all inter-component communication goes through the main thread.
The database is stored as an in-memory data structure in the main thread. Since it is the only thread that can access the database directly, the data structures don't need to be thread-safe and can be simpler. This makes the system much easier to implement and to test, which will result in more reliable software.
The main thread will do things like give database entries for the worker threads to read, request for database entries from other server nodes, commit transactions to the database, ensure that each database entry is replicated on enough many backup nodes, execute parts of the database garbage collection algorithm etc. All actions in the main thread should execute very quickly, thousands per second, so that the system would stay responsive and have low latency at all times. All slow actions must be executed in the worker threads or in plugins that have their own thread. For example the main thread will do no I/O, but if the database needs to be persisted in a file, it will be done asynchronously in a background thread.
The worker threads do most of the work. When a task is given to a worker thread, the worker thread will deserialize the task object and begin executing it. When the task tries to read objects that have not yet been loaded from the database, the worker thread will request for the database entry from the main thread, and after receiving it the worker thread will deserialize it and continue executing the task. When the task ends, the worker thread will serialize all loaded objects and send to the main thread everything that needs to be committed (modified data, new tasks, messages to clients).
The system is crash-only software:
Crash-only software is software that crashes safely and recovers quickly. The only way to stop it is to crash it, and the only way to start it is to recover. A crash-only system is composed of crash-only components which communicate with retryable requests; faults are handled by crashing and restarting the faulty component and retrying any requests which have timed out. The resulting system is often more robust and reliable because crash recovery is a first-class citizen in the development process, rather than an afterthought, and you no longer need the extra code (and associated interfaces and bugs) for explicit shutdown. All software ought to be able to crash safely and recover quickly, but crash-only software must have these qualities, or their lack becomes quickly evident.
Dimdwarf will probably use a System.exit(0) call in a bootstrapper's shutdown hook and will fall back to using kill -9 if necessary. As one of Dimdwarf's goals is to be a reliable high-availability application server, it needs to survive crashes well. Creating it as crash-only software is a good way to make any deficiencies apparent, so that they can be noticed and fixed early.
Executing tasks
When a client sends a message to a gateway node, the gateway will determine based on the client's session that on which backend node the message should be processed. If the client sends multiple messages, they are guaranteed to be processed in the order that they were sent. The gateway will create a task for processing the message and will send that task to a backend node for execution. The system will try to execute tasks on a node that has locally available most of the data needed by the tasks, and a layer of gateway nodes allows changing the backend node without the client knowing about it. (In Darkstar there are no gateway nodes, but the tasks are executed on the node to which the client is connected. Changing the node requires co-operation from clients.)
The backend node receives the task and begins executing it in one of its worker threads. As the worker thread executes, it will request the main thread for database entries to be read. If a database entry is not available locally, it needs to be requested from another backend node over the network. When the worker thread finishes executing the task, it will commit the transaction by sending a list of all modified data to the main thread. The main thread checks that there were no transaction conflicts, saves the changes to its database and replicates the data by sending the modifications of the transaction to another backend node for backup. If some messages to clients were created during the transaction, the messages are sent to the gateway nodes to which those clients are connected, and the gateway nodes will forward the messages to the clients.
If committing the transaction failed due to a transaction conflict, the task will be retried until it passes. If a task fails due to a programming error that throws an exception, then the task will be added to a list of failed tasks together with debug information (such as all database entries read and written by the task), so that a programmer may debug the reason for task failure. A failed task may then be cancelled or retried after fixing the bug.
Tasks may schedule new tasks for later execution. When a task commits, the commit contains a list of new scheduled tasks, in addition to modified database entries and messages to clients. The system will analyze the parameters of a task and will use heuristics to predict that what database entries will be modified by the task. Then when the scheduled time for the task to be executed comes, it will be executed on a backend node that contains locally most of the data that will be accessed by the task. The backend node will also try to ensure that concurrently executing worker threads will not modify the same database entries (tasks that modify the same entries will be run sequentially on the same worker thread). The decisions, that on which backend node a task should be executed, are done on a per-task basis, so each task that originated from a particular user may possibly be executed on a different backend node. (This is different from Darkstar, which has a notion of an "identity" that owns a task, and the task will be executed on the server node to which the task owner's identity is assigned. Also Darkstar supports repeated tasks, but Dimdwarf will probably simplify it by implementing task repetition in application code level, because then the system won't need to have native support for cancelling tasks, but supporting one-time tasks will be enough.)
Database entries
Each database entry has the following: unique ID, owner, modification timestamp and data. Each database entry is owned by one server node, and only that server node is allowed to write the entry. The other server nodes may only read the entry. For some other node to write the entry, it first needs to request for the ownership of the entry, and only after becoming the new owner can it write the entry.
The database uses multiversion concurrency control, so that each task works with a snapshot view of the database's data. When a task commits its modifications, the system will check the modification timestamps of the database entries to make sure that no other task modified them concurrently. This does not require locking, which may in some cases improve and in some cases lower performance (if there is much contention and the system's heuristics do not compensate for it well enough). The transaction isolation level is snapshot isolation.
When a task running in a worker thread needs to read a database entry, it will send a read request to the main thread. The main thread will check its local database, whether the requested entry is there. If it is, the main thread will respond to the worker thread with the requested data. If the entry is not in the local database or cache, the main thread will ask from a directory node that which backend node is the current owner of the entry. Then the main thread will ask for that backend node to send it a copy of the database entry. When it receives the copy, it will forward it to the worker thread that originally requested it.
When a task running in a worker thread commits, it will create a list of all database entries that were modified during the task. This includes also tasks that were created, messages that were sent to clients and whatever other data needs to be committed. When the main thread receives the commit request, it will check that none of the database entries were modified concurrently. This is done by comparing the last modified timestamps of the database entries. The main thread will also make sure that the task read a consistent snapshot view of the database. If there is a transaction conflict, the commit request is discarded and the task is retried. If there are no transaction conflicts, the main thread will store the changes to its database, send any messages for clients to the gateway nodes, and send the modified database entries to the current server node's backup node for replication. It will also send the updated database entries to other server nodes that have previously requested for a copy of that database entry, so that they would have the latest version of the entry.
When committing, the current server node needs to be the owner node of all modified database entries. If this is not so, the main thread will need to request for the ownership of the entries from their current owner. First it needs to find out who is the current owner. Each database entry contains information that which server node is the owner of that entry version. The information can also be received from the directory nodes. When the ownership of a database entry is transferred, the old owner will tell about the ownership transfer to all other server nodes that it knows have a copy of the database entry. Then those server nodes can decide to ask the new owner to send them updated versions of the database entry, in case it's an entry that they will read often.
It is not possible to delete database entries manually. A database garbage collector will check for unreachable database entries periodically and will delete entries that are not anymore used. The garbage collector algorithm will probably be based on the paper An Efficient On-the-Fly Cycle Collection. A number of different algorithms can be implemented to find out which one of them suits Dimdwarf and different types of applications the best.
Failover
Each backend node has one or more other backend nodes assigned as its backups. The server node that is the owner of a database entry is called the master node and it contains the master copy of the database entry. The server nodes that contain backup copies of the database entry are called backup nodes.
When the master node modifies some master copies, the master node sends to its backup nodes a list of all updates done during the transaction. Then the backup nodes update their backup copies to reflect the latest version from the master node. To ensure consistency, the updates of a transaction are always replicated as an atomic unit.
When a server node crashes, the first server node to notice it will signal the other server nodes about the crash and they will coordinate the failover. One of the crashed node's backup nodes takes up the responsibility of replacing the crashed node and then promotes its backup copies to master copies. The whole cluster is notified about the failover, that which backup node replaced which master node, so that the other server nodes may update their cached information about where each master copy is.
If there are multiple backup nodes, they may coordinate with each other that which one of them has the latest backup copies of the failed node's database entries. Also, because the owner of a master copy may change at any time, the backup nodes need to be notified about ownership transfers, so that they would not think that they are still the backup node of some database entry, even though its ownership has been transferred to a new master node which has different backup nodes. A suitable failover algorithm needs to be designed. It might be necessary to have additional checks that which node in the cluster has the latest backup copy, maybe by collecting that information in the directory nodes.
Although also other server nodes than backup nodes may contain copies of a database entry, those copies will not be promoted to master copies, because they are not guaranteed to contain a consistent view of the data that was committed. If a transaction modifies database entries X and Y, at failover the same version of both of them needs to be recovered. The backup node is guaranteed to have the same version of both X and Y, because the master node always sends it a list of all updates within a transaction, but other nodes may receive an updated copy of either X or Y if they are interested in only one of them.
The other server node types (gateway, directory, coordinator) may also have backup nodes if they contain information that would be slow to rebuild.
Session and application contexts
When a client connects to a gateway node, a session is created for it. The sessions are decoupled from authentication and user accounts. The application will need to authenticate the users itself and decide how to handle cases where the same user connects to the server multiple times.
Each session has a map of objects associated with it. It can be used to bind objects to a session, for example to store information about whether the session has been authenticated. It will also be used by the dependency injection container (Guice) to implement a session scope. The whole application has a similar map of objects, which will be used to implement an application scope.
Objects in session and application scopes will be persisted in the database. It will also be possible to have non-persisted scopes, such as a server node specific singleton scope, in case the application code needs additional services that can not be implemented as normal tasks.
Session messages and multicast channels
When application code knows the session ID of some client, it can send messages to that client. As in Darkstar, there are two categories of sending messages: session messages for one client and multicast channels for multiple clients.
Messages from a session are guaranteed to be processed in the same order as they were sent. The cluster might use an algorithm similar to the Quake 3 networking model, so that the gateway will forward to the backend nodes a list of messages from the client, which have not yet been acknowledged to have been executed. In the backend side, the processing of session messages will modify a variable in the session's database entry to acknowledge the last executed message. Transactions will make sure that all session messages are processed once and in the right order.
Multicast channels will operate the same way as session messages, except that the messages are sent to multiple sessions and it will be possible to have channels with an unreliable transport. When application code sends a message to a channel, the system will list all sessions that are subscribed to that channel. It will partition the sessions based on the gateway node to which the clients are connected and will forward the message to those gateway nodes. The gateway nodes in turn will forward the messages to individual clients.
Receiving messages from clients through session messages or channels is done using message listeners, similar to Darkstar. The application code will implement a message listener interface and register it to a session or channel. Then the method of that listener will be called in a new task when messages are received from clients.
Supporting services
A Dimdwarf cluster requires also some additional services: A tracker keeps a list of all server nodes in a cluster, so that it would be possible to connect to a cluster without knowing the IPs and ports of the server nodes. A bootstrap process runs on each physical machine and it has the power to start and to kill server nodes on that machine. The trackers and bootstrappers can be used by management tools to control the cluster.
There will be command line tools for managing the cluster. There will be commands for installing an application in a new cluster, for adding and removing servers in the cluster, for upgrading the application version, for shutting down a cluster etc.
Application upgrades will happen on-the-fly. First server nodes which have the new application code are started alongside the existing server nodes. Then the new server nodes begin to mirror the data in the old server nodes the same way as backup nodes. Finally, in one cluster-wide move, the new server nodes take over and begin executing the tasks instead of the old server nodes. The serialized data in the database will be upgraded on-the-fly as it is read by tasks on the new server nodes.
Dimdwarf may be extended by writing plugins. There will be need for advanced management, monitoring and profiling tools. For example I'm planning on creating a commercial profiler that will give detailed information about all tasks and server-to-server messages, so that it would be possible to know exactly what is happening in the cluster and in which order. It will be possible to record all events in the cluster and then use the profiler to step through the recorded events, moving forwards and backwards in time.